OK, so you use Gradle to build your Java projects. And if you use the application plugin in Gradle then you get also the startup script generation so you can ship that straight into your prod servers. Thing is, the application plugin generates a “standard” script — which does include the classpath and a whole […]
Posts Tagged: linux

Using OS-level Signals in Java for Monitoring
For those of you familiar to monitoring Java applications, I’m sure the first thing that springs to mind is JMX. And I agree, that is a nice framework to provide various app insights for tracking and monitoring. The trouble with JMX though, if you haven’t got a system in place already to collect this data […]

Tracking Users Online — Part 2
First release of this project on Github is now out there. And as promised in my “pilot” post of this series, this post will walk you through what went into this release and why. The project itself as you recall is available on Github in this repository: https://github.com/liviutudor/PixelServer. The version for this release is pixelserver-1.0.0 […]
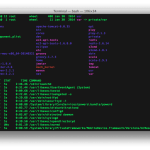
wc-minus-l
Quite a while back, (and I mean quite a while back, that’s been enough water under the bridge so I can now tell the story 🙂 ) I used to work for this guy who quite frankly was way out of his depth in the position he was in. He was my (and others’) boss […]
(Very Very Simple) Bash Script to Delete Old Log Files
So here’s the deal: you have an application running on a Linux box which generates log files. And these files keep mounting up and grow and grow and grow in both number and size and you have start considering cleaning up old logs which you don’t use anymore. I know about logrotate, it’s an awesome […]
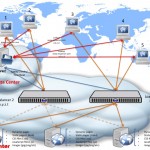
CDN — The Basics — Part 2
In the previous post, “CDN — The Basics — Part 1”, we got as far as looking at the situation where a load ballancer is employed in front of a set of identical web servers, and the DNS is handled externally by a dedicated DNS server, potentially in a different cloud/region/data center. As it has […]
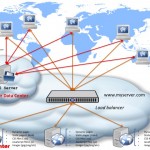
CDN — The Basics — Part 1
I wish I could put a “1 out of N” at the end of this post title, however, I have no ideas how far this will go unfortunately; I do however realise that the more I go into details about this subject the more there is to be said about it. And what I have […]

Application Monitoring and Management using Sun’s JMX/HTML Interface
This is something I wanted to write about a while back – while there are articles on the net about using JMX in a Java application to keep an eye on how it ticks, or manage its running cycle, I think there is still a large number of users out there who are somewhat reluctant […]
Configure autofs auto.smb on Debian Linux
Yet another post from my old website brought back to life — just as with the previous such posts, I hope this still stands. Nowadays I’ve moved most of my “infrastructure” to Amazon, I don’t have to use this anymore, but I remember at the time having to do a bit of research into this […]
Automating iptables on Debian Linux
It’s interesting to dwell occasionally into researching how people are reaching my blog and what are they looking for when they do so. As you have seen so recently I have brought back a few old articles that seem to have triggered the attention of some people on the net — at least that’s what […]
About Me
Technologist. MarTech. User acquisition at scale. Advisor. Speaker.







