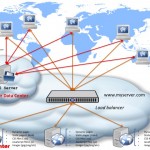
We looked in the previous post in these series on how to employ multiple load balancers to scale out your web app, however, so far the multiple load balancers were only used in a live/stand-by scenario, such as at any moment in time only one load balancer was active, while the other(s) were on standby, and the system employed (be it DNS or via a virtual IP etc) can switch from the live one to a stand-by load balancer when the live one fails.
We looked in the previous post in these series on how to employ multiple load balancers to scale out your web app, however, so far the multiple load balancers were only used in a live/stand-by scenario, such as at any moment in time only one load balancer was active, while the other(s) were on standby, and the system employed (be it DNS or via a virtual IP etc) can switch from the live one to a stand-by load balancer when the live one fails.
As mentioned, this does mean that your entire incoming and outgoing HTTP traffic goes through one single load balancer — which obviously creates a bottleneck. The problem is, like with all other hardware devices, there is an upper limit in terms of the number of connections the load balancers can process — past that you are dropping traffic or your response time increases significantly, thus providing a rather poor user experience.
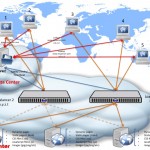
To overcome that, there is a simple change you can make to the last diagram we looked at: if you employ the likes of Dyn or UltraDNS (from Neustar) — though there are tons of others, have a look at this listing here for a start: http://www.dmoz.org/Computers/Internet/Protocols/DNS/Service_Providers/Dynamic_DNS/ — then somewhere in your console you have to specify all the external facing IP addresses of your load balancers. You can configure these as per before to be in a live/standby setup, as shown previously, OR you can have these IP addresses registered against your domain name. In which case, the DNS system will round-robin in between these IP addresses when asked by clients to perform a domain name resolution — such that first client query will be returned IP address for load balancer 1, second client will receive IP address for load balancer 2 and so on.
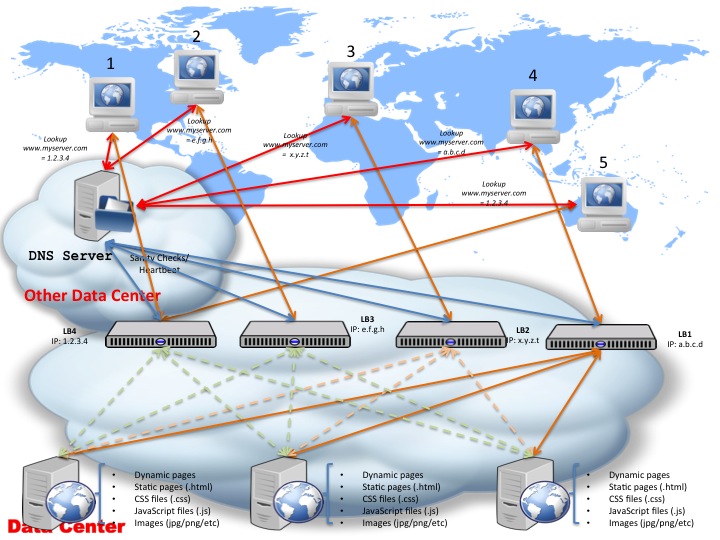
The good thing of a structure like this is that you can expand it infinitely — though obviously bear in mind we’re talking only about load balancers here, your web servers need to be able to take the load too, not just the balancers! Also, as per before, switching in between the live load balancers doesn’t have to be a round robin and can actually take into account each load balancer’s load / number of connections / etc, similarly to how load balancers route calls to the web servers. And just as before, the same issue remains: each DNS resolution will have a TTL, which means the higher the TTL the less DNS requests you will get (since clients will cache the name to IP resolution for longer), however, the longer it takes to recover from a load balancer failure.
In all the architectures we looked at so far though, the problem is still the same: all the content (static and dynamic) is served from the same server(s). This means, in a high throughput system, that valuable cycles of your CPU (not to mention bandwidth, disk I/O, memory, kernel file system cache and so on) is wasted on serving the same file over and over again. Imagine a simple web page which contains just dynamic content (returned by your web app) but which references a CSS stylesheet:
<html> <head> ... <link rel="stylesheet" type="text/css" href="main.css"/> </head> <body> <p>Some dynamic content here...</p> </body> </html> |
As mentioned above, let’s assume the dynamic content is returned by your web application (be it JSP, CGI’s, PHP etc) — however, because it references a CSS file, each client will have to download the file locally and apply the stylesheet to the page. This means that for each request to your dynamic page you have to take an extra hit to load the CSS. This hit consists typically of:
- Parse the HTTP request — which implies converting the URL to a file system path
- Load a chunk of the file into memory — so disk I/O (read) as well as memory consumption
- Write the chunk of file from memory onto network — so network I/O (write)
- Repeat 2 and 3 till the end of file
- Close file
- Close network channel — arguably this might not be always needed due to the likes of
Keep-Alivesand so on
The browsers will cache the CSS file — granted (though, of course, this is subject to HTTP headers, but most web servers will send the right headers for a static file to allow caching) — however, even in that case, a browser will issue a HTTP request (not GET, a HEAD request) as the browser will need to check whether the file needs refreshing in the cache or not. And even for such a little thing, your web server has occasionally to go to disk, check file change date/time compare to the browser one etc etc etc — so you’re still spending a lot of resources for the sake of one file, when you would want all of your server resources to be concentrated on your web application!
Ultimately, there are different requirements for serving dynamic content (say PHP code) to serving static files: for dynamic content you need CPU (for the code to execute) — for static content you need fast disk I/O and preferably lots of memory to cache the content in memory to avoid disk. Now with the evolution of web apps so much nowadays, web applications need disk too, and memory, and CPU and all sorts of other resources — so sharing those with the simple requirements of serving static files means you are lowering your web server capacity (or at least slowing down the responses).
Update: I found this post in my Drafts just now (Jun/2016). From what I recall I put together this series at the time for the Cognitive Match website and some of this information has actually trickled as guest blog posts on some other sites, various tech partners we had at the time (such as Dyn and UltraDNS etc). As such, I believe this series was finished but since that startup was long acquired by Magnetic and their website and blog disappeared, I don’t have the remaining material for this hence the sudden ending — apologies about that. Still, I thought it worth to publish this last piece as it has some relevant info.