 I have attended the other week a very interesting meetup – part of the “Scale Warriors of Silicon Valley” series (which by the way I highly recommend if you’re into that sort of “thing” – and chances are if you’re a developer in the Valley you are! 😉 ) – and as with everything I see and listen to, it can’t go un-blogged! Even more so, this talk was not just about scale, but about scaling an online advertising architecture – and since I eat advertising and everything related for breakfast, I couldn’t miss it. This particular meetup saw John Krystynak, AppLovin co-founder and VP of Engineering taking the stage and giving us an insight into how to scale up an advertising solution – with real-world examples from his company, AppLovin, which boasts nowadays about 15 billion ad impressions per day.
I have attended the other week a very interesting meetup – part of the “Scale Warriors of Silicon Valley” series (which by the way I highly recommend if you’re into that sort of “thing” – and chances are if you’re a developer in the Valley you are! 😉 ) – and as with everything I see and listen to, it can’t go un-blogged! Even more so, this talk was not just about scale, but about scaling an online advertising architecture – and since I eat advertising and everything related for breakfast, I couldn’t miss it. This particular meetup saw John Krystynak, AppLovin co-founder and VP of Engineering taking the stage and giving us an insight into how to scale up an advertising solution – with real-world examples from his company, AppLovin, which boasts nowadays about 15 billion ad impressions per day.
Just so my ramblings in this post make more sense, it is worth mentioning here that AppLovin came out of stealth mode rather recently with their mobile marketing platform that acquires and re-engages customers and they’re already boasting a huge amount of traffic through their platform (some 15 bilion ad impressions per day according to the talk). Also, the event was a joint-venture in between AppLovin and Aerospike who was kind enough to allow us to crowd up their (sweet!) office as well as provide the drinks and food – oh yes, and the bottles 😉 The other interesting side of this joint-venture is that of course, as John revealed in his talk, they use Aerospike’s solution in AppLovin. Aerospike, for those of you unaware of this, provides an open-source NoSQL database combining both transactions and analytics with ACID principles.
I will not go through all the presentation slide by slide – talking to Aerospike, I understand that they will be making the whole recording available on their YouTube channel soon so keep an eye on this: https://www.youtube.com/user/AerospikeTV. I will post an update here the moment the recording becomes available – and also will follow up with any links to a slide-share or the likes, wherever the 2 companies decide to upload the full set of slides. For now though I will include the ones which I found interesting enough to write about.
First of all, before I dive in, I have to say, there are very few presentations I’ve seen where I have encountered such a level of being frank – Mike Nolet from AppNexus springs to mind, as I loved the way he openly spoke about how much a pain in the ass (yup, his exact words) load balancers can be 🙂 (Side note to self: now that I said that it occurred to me a slight name coincidence: AppNexus and AppLovin ! Maybe that’s the winning formula there: if your company is called App…something that ought to mean that you’re a no-BS kind of person and tell it like it is? 🙂
Anyway, I diverge again, above point being that John delivered his content un-biased and un-twisted – that, believe it or not, is not that common in our industry. Maybe because working in advertising teaches a lot of people how to always twist things around and only present the nice side of things, I don’t know; but when was the last time you hear someone saying: “Man, colo replication is a pain in the backside” ? We all know that to be the case, and we all find ourselves listening on the wire for that bit of transaction getting committed in London after it’s been committed in the West Coast colo – we all know it’s a pain! But hardly anyone talks about it openly – we all sweep some of these away under the carpet during such technical talks – because God forbid we show that we have encountered technology problems in our startup, right? As such I find it refreshing when someone talks openly about such issues – and this talk was one of those; my blog post here probably doesn’t do it too much justice, I highly encourage you to watch the full recording when it comes out on YouTube!
One of the first thing John stated in clear from the beginning was this: if you’re building a solution (advertising or not) which is meant to scale to 15 bilion transactions per day or more, you will not find off-the-shelf, pre-packaged solutions and components for this. You have to spend time hand-crafting pretty much everything you need. Sure you find yourself using various frameworks, libraries and solutions for various part of the system but even then these will only get some of the work done – the rest of it you will have to sweat over yourself.
Anyone thinking “Oh, I need some sort of ad server – let me see: I’ll throw in some caching, some big database, some nosql for good measure and some nodejs and that will do” is just an idiot. And sadly, I’ve actually met people who tried to do that – some of them actually managed to even blind occasionally investors with their pedigree and their use of hot keywords and got some funding but went nowhere! Exactly because anything that is complicated needs a lot of handcrafting – in terms of code, infrastructure, architecture and so on. This might some obvious, but a lot of people seem to forget it and as such I love it when someone states it clearly: It’s not easy to build a complicated solution!
(In particular, it turns out that in AppLovin they ended up implementing their own messaging solution because the ones they explored didn’t provide the level of both guaranteed delivery as well as speed.)
In line with the above, John touched on another subject dear to my heart: technology adoption. I “love” it (please, please note the quotes!) when you get a head of some sort of department/group/company who comes to a meeting and says to their developers: “Hey guys, I’ve read that Scala is so much faster than Java, we should switch to that!”. And then from there on everyone is running around like headless chickens trying to push Scala left-right-and-center into the platform. And my question is always the same in the above situation: “WHY?” Why do we have to switch to Scala? Is for instance speed of our framework an issue? If we’re talking about gaining 1second for the execution of an ETL process which runs once a week I’d argue we’re better off leaving it unchanged for instance. It might be the case that technology A is better than technology B indeed, but have we measured it that it is the case with our solution too? Also, ok, I get it, we can get stuff out the door much quicker with Scala, let’s say – but we have zilch, nada, no developers with Scala expertise, do you know what that means? It means a 6 months recruitment effort and then another 3-4-5 months for those guys to get their head around what our current system does and try to re-architect it in Scala. So one year… And the list goes on and on. (By the way, I’ve used Scala in this example since the “Java vs Scala” it’s been a hot topic for a while – but you can use any other technology or framework in the above example and my point still stands.)
Don’t get me wrong, if someone comes and says: “Hey guys, I’ve done a quick research here it looks that switching this module to Scala we improve our throughout 2 or 3 fold at a first glance” – that is something worthy of consideration: someone put effort to actually analyze the technology in context and came up with some data to look at! Even then, there might still be counter-arguments for proceeding with that technology, but at least the decisions are not being made randomly, but rather based on analysis. The embracing of technologies “in blind” is the one that gets me – I’m looking at you, CTO’s of Silicon Valley and worldwide, you know who you are 🙂 The ones who always throw “stuff” in your tech stack in the secret hope that something will come out of this chaos, after all this is how the Universe was created, right? 🙂

The above slide taken from the presentation touches on most aspects worth considering when adopting technology into a stack – I’d have a few things re-shuffled if it was for me (frankly, “Does it simplify our world” would be my first – but I’m too much of a pragmatic character so perhaps not the best to judge that order) — but the list still stands. In particular the “Does it fail nicely” definitely rubbed me the right way – I’ve seen setups with ActiveMQ long dead and messages going into “no mans land” without any awareness from other components in the system, so I have a lot of respect for someone who looks at things like this!

The above slide is a stack evolution for AppLovin – I am not going to comment on my feelings about the usage of php vs Java vs C++ or Aerospike vs Redis or any other comparisons like this, but just want to point out one important aspect that this slide brings in, which I believe is in line with the previous slide and technology adoption: the right tool for the right job! When you’re starting out and looking to get to market as soon as you can, and your developers base has strong php skills then go for php. Get your first version of the platform “out there” then start iterating. It will be maybe slower than an equivalent version written in Java but will get you the first customers and will set up the platform for expansion and development! There will be a lot of peeps out there (ahem, myself included :D) to tell you that php sucks, but that doesn’t mean you shouldn’t use it! Instead it might just mean that you shouldn’t use it long term. Look at Twitter, that’s another example for a platform which started in Ruby on Rails and nowadays are one of the strongest contributors to things like Scalding as well as being a huge supporter for Scala. However, Ruby on Rails made sense for them in version 1!
This is another thing that gets often forgotten, but when dealing with starting up a project, you ought to start small and iterate – start with C++ from day zero and you will find yourself you will build maybe a super-optimized product but by the time you get to market someone else already got there and ate your lunch!
Last but not least, this slide captured everyone’s attention: it is a rating chart, AppLovin uses internally to rate their datastore solutions. (Green is pretty good, amber is so-so and red means rubbish by the way.) As soon as this slide came up all the cameras in the room starting going nuts – as I think a lot of people expected this to be an universal rating of all such datastores. However, as John points out, this is the rating of these solutions based on their performance within the AppLovin tech stack. Quite a subtle difference you’d argue, though the implications of it are huge!
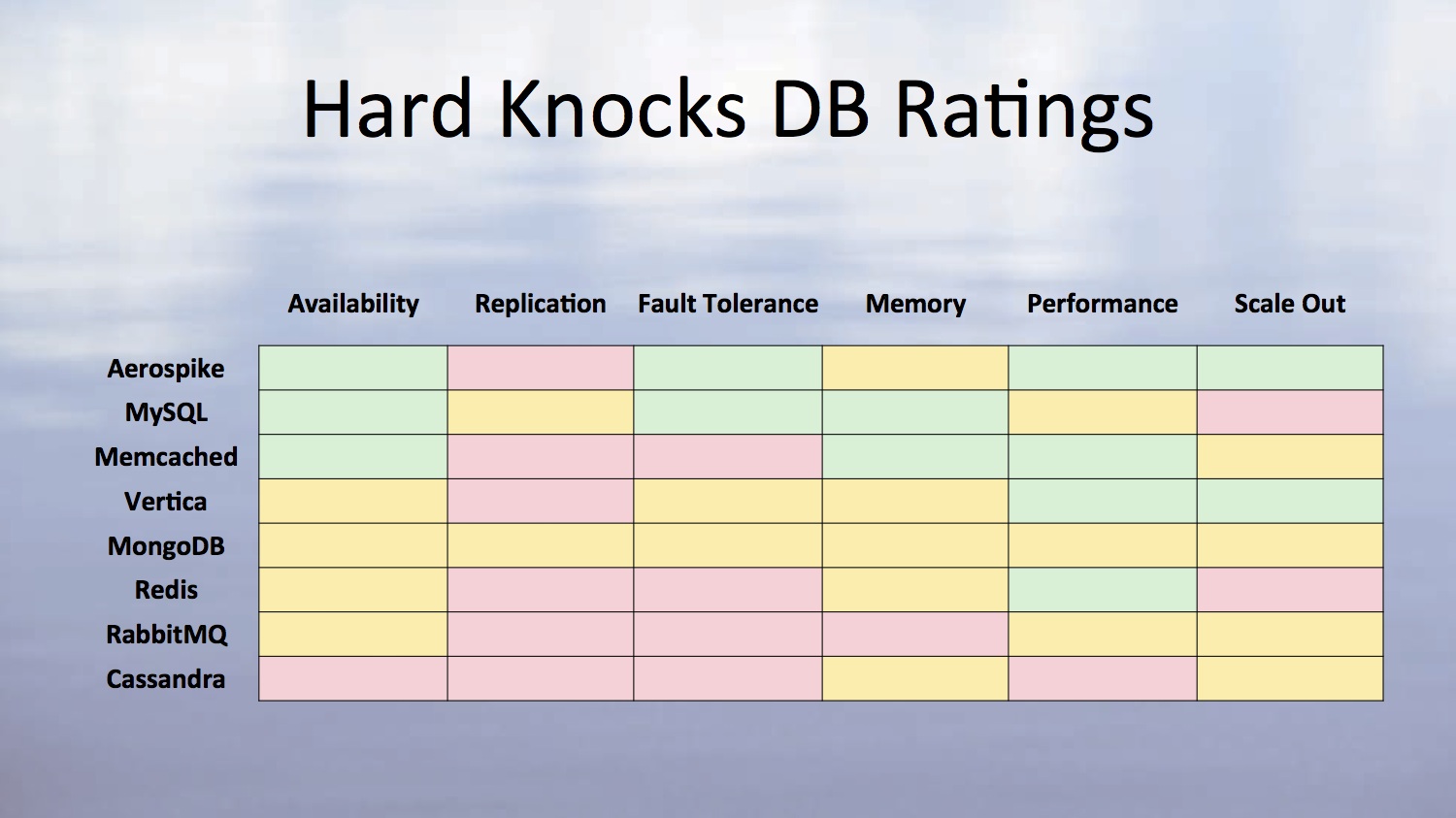
As with the previous slides, when the idea of “right tool for the right job” was stressed a few times, the same applies here: it’s quite likely that Aerospike beats MongoDB in certain environments and setups but the way it is being used in AppLovin creates problems when it comes to replication! Maybe RabbitMQ boasts high availability, but in their current environment that availability is a bit so-and-so!
Part of the reasons why we techies go to these meetups is to keep up-to-date with trends and tools and frameworks in our field – and often we are blinded by astonishing figures showing that database X performs 100 times faster than database Y. Only to find out when we deploy it in our stack that it soooo doesn’t! Then we go back to read the way the test was performed and we find out that it only applies to a write-heavy environment…. And we use it mainly for reading… And at that point we are already committed to using it as it’s deep embedded into our stack!
I’ve seen this done, as a side note, in a platform I came across recently with Couchbase – absolutely great product, I have no doubt about it.. when used correctly! Yet I’ve seen a team spending a few months transitioning from a Cassandra-based implementation to Couchbase only to find out that the performance difference in their case was negligible – not a good way to spend development effort if you ask me!
The fact that the AppLovin teams took the time to rate this in their current environment is refreshing – and I would urge everyone to do the same for their current tech stack. First of all it allows you to give an honest evaluation of your current problems – if you look at the above slide you can spot right away that replication is an issue still in AppLovin across all of their tech stack. This, no doubt, allows them to start investigating solutions which have a better replication or also develop in-house solutions for it. Things like memory consumption for instance can be spotted at a glance – so far everything performs ok on that level so for the near future that shouldn’t be a problem for your datacenter team, and they can focus their efforts in other directions.
Secondly, it also defines a set of parameters you should consider when you select another framework or technology to add to your stack. Is there a new key/value store out there? Good, let’s investigate it – we know already we need to look at things like replication, memory, scaling out and so on – so you already have a basic system to decide early whether that particular technology is going to create problems for you or bring any benefits in!
It also gives you an idea of what frameworks you’ve already looked at. Say a new techie starts tomorrow, he looks at your Redis setup and says “Hey guys, you know we can use Aerospike to improve our scaling out as well as the fault tolerance aspect?”. You just bring up the chart and say : “Yup, we know that, look, we already looked at this and there’s still problems with replication. So if you ought to look into Aerospike, see if you can do anything on the replication front.” And you’ve already made his/her work easier as they will know exactly where to look!
Also, regarding the above chart, it doesn’t matter how AppLovin rated these solutions – and I honestly hope no one who attended the meetup will take this chart as an industry standard (sorry, John!) – the important lesson I think to learn here is that YOU need to have your own rating system and select what works for YOU. In fact John took the time to explain just that: this is the way AppLovin rates these solutions in their current setup. It might even be the case that future changes in their architecture will see a change in the above ratings – but at least, this gives them a way to measure and evaluate technologies (data stores in this instance).
Ultimately though, scaling up a solution to the current scale AppLovin is experiencing is no easy task. There is no silver bullet for it and whichever way you go about it requires hard work. I remember one question asked from the audience was regarding what innovation did AppLovin bring with their platform – and John’s answer nailed it: “Do you think it’s easy to keep those front-end servers answering to RTB’s systems in milliseconds and deciding whether to bid or not on an adview?”. It’s definitely not, and if you worked with (or within!) any online adserving solutions you will definitely agree with John’s view on this. And even more, I challenge you not to agree with most of the points he made during his talk, as I think they are spot on and anyone who’s taking on the mission to build an ad-serving platform ought to look at these slides!










Video of the presentation, hot off YouTube 🙂 https://www.youtube.com/watch?v=mJbflVZJD4g